Agentic Service Proof of Concept
Background
An established technology company was developing a new version of its platform that allowed users to customise it to their needs. This benefited both customers and the organisation but also revealed complications in how users accessed the platform’s data.
The client noticed a pattern: users persistently demanded direct access to underlying data via the platform’s GraphQL API. This strained support channels, as users struggled with the complex schema or technology.
This demand highlighted a disconnect between the platform’s interface and users’ objectives. The gap in data accessibility created an opportunity to translate business intent into technical execution, eliminating the need for users to master GraphQL.
Objective
The client wanted to validate the idea of using LLMs to develop an agentic service that could assist customers in accessing data, creating queries, and manipulating data via GraphQL.
User Personas & Service Design
It was recognised early that users possessed varying levels of technical proficiency and understanding of GraphQL and supporting technology. Specific issues included:
- Knowledge Gap: Users had inconsistent competency regarding GraphQL and the underlying data source.
- Query Complexity: Many user objectives required multi-hop queries, intermediate data collection, or logical comparisons.
- Documentation Burden: Manual schema navigation was time-consuming and prone to error.
To facilitate rapid validation during the Proof of Concept (POC), I categorised users into three competency levels. This allowed for the imagining of specific assistance requirements for the agentic service:
| User Knowledge | Job | Description |
|---|---|---|
| Low | "Get me the report” | The user needs specific data outputs but has no interest or desire to interact with the underlying schema. |
| Medium | "Help me extract and customise" | The user needs to manipulate or filter existing datasets but struggles with structure traversal and relational constraints. |
| High | "Help me build and optimise" | The user understands the data and technology but wants help to design and refine complex queries, and requires tools to assist schema navigation and query optimisation. |
Technical Exploration
The proof of concept focused on exploring an architecture capable of translating natural language into valid GraphQL queries while ensuring system security. This involved weighing the trade-offs between model performance, context management, and integrating external tools into a dependable inference pipeline.
Key components explored included:
The Inference Path
In exploring the inference path, the goal was to explore the definition of a controlled pipeline to ensure that user intent was accurately translated into executable queries. I defined a minimal path:
- Preparation: GraphQL Schema types were treated as documents to enable searching.
- Planning: An agent translated the user query into a multi-step resolution plan before generating code.
- RAG Execution: Hybrid retrieval architectures were tested, combining dense semantic search, sparse keyword matching (BM25), and late-interaction models to retrieve schema definitions and field relationships.
- Permissions Check: A mechanism was required to compare retrieved GraphQL types against the user’s existing authorisation levels.
- Query Generation: A sub-agent would generate a query using the retrieved documents, benefiting context management.
- Validation & Self-Correction: The agent was constrained by structured output generation, and the output was validated against the actual schema. Any errors were fed back to the agent for a second attempt (reflection).
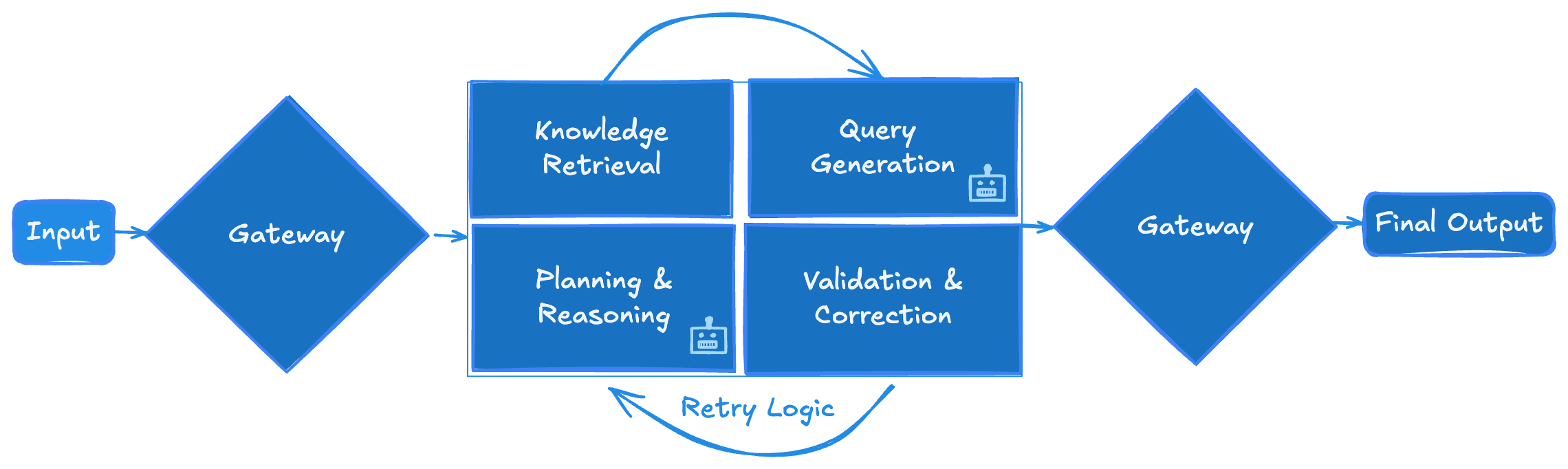
A high-level view the inference path explored during the proof of concept.
RAG Refinements
To refine the retrieval process, various techniques were tested to address common RAG failure modes such as semantic collapse and query ambiguity:
| Technique | Purpose | Outcome |
|---|---|---|
| Metadata Enrichment | Added GraphQL schema type classifications | Improved relevance scoring |
| Query Alternatives | Generated paraphrased versions of user queries | Enhanced recall |
| Dummy Answer Generation | Created synthetic Q&A pairs | Improved semantic similarity |
Strategic Recommendations
During the engagement, I identified several key topics that served to strengthen the organisation’s agentic strategy in its progress towards its data accessibility goal. These recommendations, inspired by NIST AI RMF, were made to act as enablers for safer, more reliable use of LLMs in agentic services. These included:
The 1:10:100 Rule: Early Governance as a Strategic Investment
A central recommendation was to embrace robust governance early using a Risk Treatment Framework. The main suggestion was to adopt a collaborative traffic light system to categorise and map risks like prompt injection, erroneous mutations, and data exfiltration.
Early governance adoption provides businesses with a clear path to building confidence in probabilistic system deployment. This can be strengthened by promoting a risk-thinking culture across multiple functions within an organisation. This collective understanding allows for informed decisions on risk treatment while considering an organisation’s risk appetite and commercial sensitivities. A grounded assessment may involve accepting low risks where appropriate, transferring risk to others with full knowledge of regulatory and legislative requirements, or avoiding high-risk capabilities altogether to prevent potentially devastating financial or non-financial consequences. As the 1:10:100 rule states, investing in prevention early can save significantly on correction and failure costs.
2. Leaning into ML Ops and TEVV
Another recommendation was the education of staff and developers about ML Ops and TEVV (Test, Evaluation, Verification, and Validation). Knowledge of both is critical for production-grade agentic system deployments and helps with interlacing risk mitigations within teams’ existing practices. Both ML Ops and TEVV should be viewed as an enhancement to the toolkit of teams building agentic services rather than displacing or superseding traditional methods:
- Complementing the Foundation: Teams are familiar with the use of unit and integration tests to verify the consistency and interaction of service elements, but not with elements of ML Ops and TEVV practices that provide monitoring and observability against failure modes.
- Managing Model Drift: Because third-party model providers update independently, a continuous feedback loop should be implemented to detect divergence.
- Operational Readiness: To ensure transparent evaluation, teams must implement indicators for relevance and faithfulness while capturing detailed reasoning traces. These tools are essential for verifying grounding and spotting hallucinations. Being operationally ready means proactively accounting for the probabilistic - and therefore non-deterministic - nature of large language models.
- Adversarial Monitoring: Malicious actors manipulate inputs to bypass a system’s guardrails, forcing it to generate unwanted content, reveal system instructions, or act outside its intended scope. Integrating both automated detection and team-based red-teaming ensures that defences evolve alongside emerging prompt injection and jailbreaking techniques.
Retrospective
Several factors influenced a pause of the proof of concept to ensure long-term viability of the organisation’s goal:
- Service Boundary Definition: Clarity was required on where the responsibility for multi-hop logic should lie, either within the agent's autonomy or via user-guided interaction. Human-in-loop was recommended but consideration for designed friction needed to be made to guard against over-reliance and complacency.
- Resource Allocation: The discovery identified a requirement for specific expertise (e.g., security, governance, and MLOps) to maintain a production-grade service.
- Maturity Alignment: The engagement underscored the need to align the project with the organisation's evolving risk appetite, paying attention to the transition from deterministic software to stochastic systems.
Conclusion
The proof of concept provided a map of architecture and governance concerns. The decision to pause at the proof of concept stage reflected a prudent decision by the client to evaluate its priorities and ensure that any future efforts would be supported with a robust framework.